Note
Go to the end to download the full example code.
Joint pca decoding¶
Takes high gamma filtered data with event labels from multiple subjects and performs joint pca decoding
from ieeg.navigate import channel_outlier_marker, trial_ieeg
from ieeg.io import raw_from_layout
from ieeg.timefreq.utils import crop_pad
from ieeg.timefreq import gamma
from ieeg.decoding.joint_pca.alignment_methods import JointPCADecomp
from ieeg.arrays.label import Labels
from bids import BIDSLayout
import mne
import numpy as np
from sklearn.model_selection import KFold
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
Load Data¶
bids_root = mne.datasets.epilepsy_ecog.data_path()
layout = BIDSLayout(bids_root)
raw = raw_from_layout(layout,
subject="pt1",
preload=True,
extension=".vhdr")
Extracting parameters from /home/docs/mne_data/MNE-epilepsy-ecog-data/sub-pt1/ses-presurgery/ieeg/sub-pt1_ses-presurgery_task-ictal_ieeg.vhdr...
Setting channel info structure...
Reading events from /home/docs/mne_data/MNE-epilepsy-ecog-data/sub-pt1/ses-presurgery/ieeg/sub-pt1_ses-presurgery_task-ictal_events.tsv.
Reading channel info from /home/docs/mne_data/MNE-epilepsy-ecog-data/sub-pt1/ses-presurgery/ieeg/sub-pt1_ses-presurgery_task-ictal_channels.tsv.
Reading electrode coords from /home/docs/mne_data/MNE-epilepsy-ecog-data/sub-pt1/ses-presurgery/ieeg/sub-pt1_ses-presurgery_space-fsaverage_electrodes.tsv.
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/checkouts/latest/ieeg/io.py:283: RuntimeWarning: DigMontage is only a subset of info. There are 3 channel positions not present in the DigMontage. The channels missing from the montage are:
['RQ1', 'RQ2', 'N/A'].
Consider using inst.rename_channels to match the montage nomenclature, or inst.set_channel_types if these are not EEG channels, or use the on_missing parameter if the channel positions are allowed to be unknown in your analyses.
whole_raw = read_raw_bids(bids_path=BIDS_path, verbose=verbose)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/checkouts/latest/ieeg/io.py:283: RuntimeWarning: Unable to map the following column(s) to to MNE:
outcome: S
engel_score: 1.0
ilae_score: 2.0
date_follow_up: n/a
ethnicity: 0.0
years_follow_up: 3.0
site: NIH
clinical_complexity: 1.0
whole_raw = read_raw_bids(bids_path=BIDS_path, verbose=verbose)
Reading 0 ... 269079 = 0.000 ... 269.079 secs...
Preprocessing¶
# Mark channel outliers as bad
channel_outlier_marker(raw, 5)
# Exclude bad channels, then load the good channels into memory
raw.drop_channels(raw.info['bads'])
good = raw.copy()
good.load_data()
# Remove intermediates for memory efficiency
del raw
# CAR (common average reference)
good.set_eeg_reference()
outlier round 1 channels: ['N/A']
outlier round 2 channels: ['N/A', 'RQ2']
outlier round 3 channels: ['N/A', 'RQ2', 'AST2']
outlier round 4 channels: ['N/A', 'RQ2', 'AST2', 'AD3']
outlier round 5 channels: ['N/A', 'RQ2', 'AST2', 'AD3', 'PD4']
outlier round 6 channels: ['N/A', 'RQ2', 'AST2', 'AD3', 'PD4', 'G32']
ECoG channel type selected for re-referencing
Applying average reference.
Applying a custom ('ECoG',) reference.
High Gamma Filter¶
# extract the epochs of interest
ev1 = trial_ieeg(good, ["PD", "G16", "SLT1-3"], (-1, 2), preload=True)
base = trial_ieeg(good, "onset", (-1, 0.5), preload=True)
# extract high gamma power
gamma.extract(ev1, copy=False, n_jobs=1)
gamma.extract(base, copy=False, n_jobs=1)
# trim 0.5 seconds on the beginning and end of the data (edge artifacts)
crop_pad(ev1, "500ms")
crop_pad(base, "500ms")
# remove intermediates
del good
Used Annotations descriptions: [np.str_('AD1-4, ATT1,2'), np.str_('AST1,3'), np.str_('G16'), np.str_('PD'), np.str_('SLT1-3'), np.str_('offset'), np.str_('onset')]
Not setting metadata
3 matching events found
No baseline correction applied
0 projection items activated
Using data from preloaded Raw for 3 events and 3001 original time points ...
0 bad epochs dropped
Used Annotations descriptions: [np.str_('AD1-4, ATT1,2'), np.str_('AST1,3'), np.str_('G16'), np.str_('PD'), np.str_('SLT1-3'), np.str_('offset'), np.str_('onset')]
Not setting metadata
1 matching events found
No baseline correction applied
0 projection items activated
Using data from preloaded Raw for 1 events and 1501 original time points ...
0 bad epochs dropped
0%| | 0/3 [00:00<?, ?it/s]
67%|██████▋ | 2/3 [00:00<00:00, 19.90it/s]
100%|██████████| 3/3 [00:00<00:00, 20.61it/s]
0%| | 0/1 [00:00<?, ?it/s]
100%|██████████| 1/1 [00:00<00:00, 40.70it/s]
Extract data and labels¶
data1 = ev1.get_data(slice(0, 40)).swapaxes(1, 2)
data2 = ev1.get_data(slice(41, 81)).swapaxes(1, 2)
phon_labels = Labels([["AD1-4, ATT1,2", "PD", "G16"]]).T
Decoding¶
n_iter = 5
cv = KFold(n_splits=3, shuffle=True, random_state=42)
y_true_all, y_pred_all = [], []
for _ in range(n_iter): # repeat K-fold evaluation n_iter times
for train_idx, test_idx in cv.split(data1, phon_labels):
# split X1 into train and test
X1_train, y1_train = data1[train_idx], phon_labels[train_idx]
X1_test, y1_test = data1[test_idx], phon_labels[test_idx]
# X2, y2 are only pooled with X1 for training, so no splitting
X2, y2 = data2, phon_labels
# Jointly decompose X1 and X2 to shared subspace via PCA
jointPCA = JointPCADecomp(n_components=3)
X1_train, X2 = jointPCA.fit_transform([X1_train, X2], [y1_train, y2])
# Transform X1_test to shared subspace
X1_test = jointPCA.transform(X1_test, idx=0)
# Reshape data into trials x features (features = PCs*time)
X1_train = X1_train.reshape(X1_train.shape[0], -1)
X1_test = X1_test.reshape(X1_test.shape[0], -1)
X2 = X2.reshape(X2.shape[0], -1)
# pool X1 training data and X2 data together
X_train = np.concatenate((X1_train, X2), axis=0)
y_train = np.concatenate((y1_train, y2), axis=0)
# classification via a linear SVM
clf = SVC(kernel='linear')
clf.fit(X_train, y_train)
y_pred = clf.predict(X1_test)
# store results
y_true_all.extend(y1_test)
y_pred_all.extend(y_pred)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/docs/checkouts/readthedocs.org/user_builds/ieeg-pipelines/conda/latest/lib/python3.12/site-packages/sklearn/utils/validation.py:1406: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
Results - Confusion Matrix¶
cmat = confusion_matrix(y_true_all, y_pred_all)
disp = ConfusionMatrixDisplay(cmat, display_labels=phon_labels)
disp.plot()
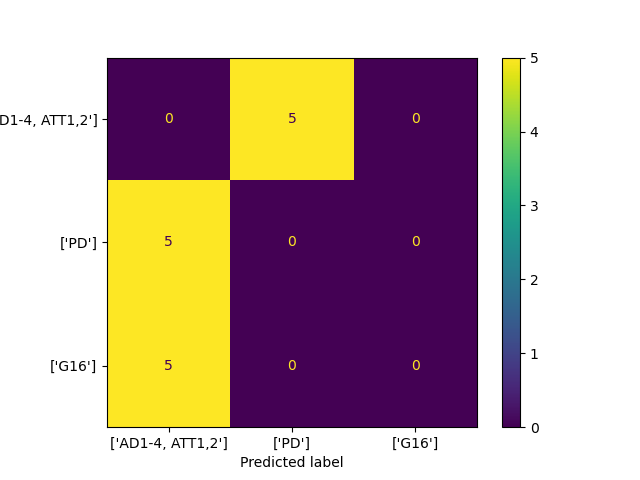
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay object at 0x74b0aa89b350>
Total running time of the script: (0 minutes 3.227 seconds)
Estimated memory usage: 1271 MB
Related examples


